Writing an Nginx-like web server from scratch in C++
Understanding the HTTP protocol and low-level network programming to build a robust web server in C++17 — one of my favorite projects at 42.
Automatically generated audio:
Overview of HTTP
When you enter a website name in a browser’s address bar, it first gets translated into an IP address 1 IP stands for Internet Protocol via a process called DNS resolution 2 DNS stands for Domain Name System . This IP address denotes the public address of a computer. A public IP address is the internet equivalent of the address of a physical building — anybody can send letters to this address. The browser then sends a message to this IP address asking for a website, i.e., asking for the resource at that location (URL) — the resource is usually an HTML document. A computer can only receive messages on an IP address if a program is “listening” for them. That program is the web server. A server is simply a computer program whose job is to continuously listen for incoming requests, “understand” (parse) those requests, and respond accordingly. In common usage, the word “server” usually refers to the computer (hardware) because that computer’s entire purpose in life is to respond to requests from the web. But it is the server program/application (the software) that truly deserves the name “server” because any computer can be a server, including your laptop and your phone, and you can still do other things on that computer while that server runs in the background.
In our example of entering a website name in the browser, the server may simply send back a default file (called an index file, usually an HTML file), which we can say is the homepage of that website. This is just the beginning of the conversation between your browser and the server. When the browser parses that HTML file to display it to you, it usually finds other resources mentioned in the HTML (e.g., images, CSS files, JavaScript, etc.), so it sends individual requests to the server for each of those resources (files). Then, as the server sends the requested files one by one, the browser displays them on the page as they are received. These days, all of this (and more!) happens in a fraction of a second. Your interaction with the page will then determine the next cycle of messages being sent back and forth between the browser and the server. In most of the messages that the browser sends, it is requesting a file (e.g., an HTML file or an image), but the browser can also send data for the server to save, e.g, when you upload an image or fill out a form. In addition to simply serving files saved on the server (called static files), it is also possible for a server to generate files on the fly based on some pre-programmed logic, e.g., based on user interaction with the website. A server can also delegate some of its tasks to other programs running on the same machine. E.g., it can give a received request to a Python program and then send the user the output of the Python program.
The “language” that the browser and the server use to communicate with each other is called HTTP, which stands for Hypertext Transfer Protocol. Just like any other communication protocol, it defines the rules of the communication. A human example (somewhat dated) is the protocol of saying “over” after finishing sending a message on a radio transceiver, such as in military radio communication or on walkie-talkies, if you are old enough to remember those! The HTTP protocol was invented in the early 1990s by Tim Berners-Lee, who is the inventor of the broader World Wide Web and HTML (he did so while working at CERN, a European nuclear research agency!). Today, the Internet Engineering Task Force (IETF) is the body that is responsible for standardizing the protocol. The legendary HTTP/1.1, the specific version of HTTP first published in 1997, remained the most widely used HTTP protocol on the web for almost two decades. HTTP/2, published in 2015, has now largely overtaken it, and HTTP/3 is quickly gaining support, thanks to the performance benefits of each subsequent generation. HTTP/1.1 used a simple plain-text format, which made it very human-readable — somewhat surprisingly, because it could easily have been more cryptic, similar to assembly language or even binary (HTTP/2 and HTTP/3 utilize binary encoding for efficiency).
A concrete example of HTTP communication
Let’s take a concrete example to better understand HTTP. Let us visit info.cern.ch, the first website ever created!
When you enter info.cern.ch into the browser, a DNS lookup takes place to resolve info.cern.ch into an IP address, which happens to be 188.184.67.127 for this website (this is an IPv4 address). The browser now knows which building (as it were) to send the message to. It actually sends a message to the IP:port combination 188.184.67.127:443 — the part after the : is called the port. If the IP address were an address of a building, the port would be the specific apartment number within the building. 443 is the standard port used for HTTPS requests — the ‘S’ stands for Secure and signifies that the data sent back and forth will be encrypted for added security. In the past, using the less secure version of HTTP, the browser would have used 188.184.67.127:80, where 80 denotes the standard HTTP port.
The exact HTTP request that the browser sends depends on things like your specific browser and operating system, but it would be something like this when you visit info.cern.ch:
GET / HTTP/1.1
Host: info.cern.ch
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:140.0) Gecko/20100101 Firefox/140.0
Accept: */*The first line is the most important: It uses one of the HTTP methods, GET, to request the resource at location / (denoting the root of the domain).
Here is what the server responds with:
HTTP/1.1 200 OK
Date: Tue, 15 Jul 2025 19:09:50 GMT
Server: Apache
Last-Modified: Wed, 05 Feb 2014 16:00:31 GMT
ETag: "286-4f1aadb3105c0"
Accept-Ranges: bytes
Content-Length: 646
Connection: close
Content-Type: text/html
<html><head></head><body><header>
<title>http://info.cern.ch</title>
</header>
<h1>http://info.cern.ch - home of the first website</h1>
<p>From here you can:</p>
<ul>
<li><a href="http://info.cern.ch/hypertext/WWW/TheProject.html">Browse the first website</a></li>
<li><a href="http://line-mode.cern.ch/www/hypertext/WWW/TheProject.html">Browse the first website using the line-mode browser simulator</a></li>
<li><a href="http://home.web.cern.ch/topics/birth-web">Learn about the birth of the web</a></li>
<li><a href="http://home.web.cern.ch/about">Learn about CERN, the physics laboratory where the web was born</a></li>
</ul>
</body></html>The first line contains 200 OK, denoting a successful response. 200 is one of the HTTP response status codes, which are sent by the server to succinctly communicate what happened to each request. After the first line, all lines before the first empty line are the HTTP headers, and everything after that is the response body (or payload). The response body, in this case, is the contents of a very simple HTML file and is what your browser will render.
On this page (https://info.cern.ch), if you click on another link such as “Browse the first website”, the browser will send another request to the server, very similar to the previous one except that the / will be replaced by a different resource location (specified in the URL that we just clicked):
GET /hypertext/WWW/TheProject.html HTTP/1.1
Host: info.cern.ch
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:140.0) Gecko/20100101 Firefox/140.0
Accept: */*The server again sends the 200 OK response along with the contents of the file at the requested location. And so the communication between the browser and the server continues.
Nginx
So, to deploy/host a website, one needs to use a server that will serve the files related to that website. Today, the majority of the world’s websites are served using one of two open-source server applications — Nginx (pronounced “engine x”) and Apache. According to W3Techs, as of the date of writing, Nginx is used by 33.8% of all websites, while Apache is used by 27.6%. These days, many websites are being deployed “serverless”, which is a misnomer because servers are, of course, still involved, just abstracted away and managed by large cloud service providers (hyperscalers) such as AWS, instead of being directly managed by the website owner.
In order to understand how a server works, one of the best ways to get started is to get familiar with one of these commonly used open-source web server applications. Setting up an Nginx or Apache web server is rather straightforward. You can turn any computer (that is running a supported operating system) into a server. For the base case, Nginx and Apache don’t differ much, so for simplicity, let’s focus on one of them: Nginx. You need to run only a couple of commands to get a “Hello World” server up and running.
The following should work on any Debian-based Linux distribution, such as Ubuntu. To install Nginx:
sudo apt install nginxStart Nginx service (runs in the background):
sudo service nginx startNow Nginx server is already running and serving a default HTML file.
At any time, you can check the status with:
sudo service nginx statusGo to http://localhost/ in your browser, and you should see the “Welcome to nginx!” default page. This is simply the contents of this HTML file: /var/www/html/index.nginx-debian.html.
You can add an HTML file named index.html in the same directory, so it will be served instead of the default file.
sudo chown -R $USER:$USER /var/www/html # Give yourself ownership of the directory to prevent "permission denied" messages
echo "<h1>Hello world</h1>" > /var/www/html/index.html # Create an index.html with the contents "<h1>Hello world</h1>"
sudo service nginx restart # Restart Nginx for the changes to take effectNow http://localhost/ should be serving the “Hello world” page. You can change that to any HTML content and that will be served on the browser. localhost is an alias for the “loopback” IP address (usually 127.0.0.1). When you visit localhost, it is as if you were visiting your site from another computer by typing in the public IP address and port of the computer on which the server is listening (the latter requires messing with various router and firewall settings and can quickly lead to security issues).
Nginx uses a configuration file to control all aspects of how the server will behave and what it will serve. By default, the configuration file being used is /etc/nginx/sites-enabled/default. Here is a simplified version of it:
server {
listen 80; # Listening on port 80 on all IP addresses of the computer
root /var/www/html; # The directory in which all the website files will live
index index.html index.htm index.nginx-debian.html; # The file to serve (first one available in this order) when someone requests the "homepage"
server_name _; # Sets names of a virtual server such as "example.com". This name is matched with the `Host` header in incoming HTTP requests
}Writing the server in C++
Now that we have an understanding of the HTTP protocol as well as the behavior of Nginx, the most popular server application, we can start writing our own server. We will implement the HTTP/1.1 protocol.
The C++ program will take a configuration file as an argument (an example compatible with our program is provided here). This config file contains all the settings of our server.
Here is approximately what our C++ program will need to do:
- Read and parse the config file and check that it is valid.
- Save the input configuration in suitable data structures for easy retrieval as requests arrive.
- Indefinitely wait for new connections to arrive on the IP:port combination(s) specified in the config file.
- When new connections arrive, queue them suitably and accept as many as the capacity allows.
- For each accepted connection that has sent a request, parse the message and prepare a suitable response.
- Send the response and wait for further messages and further connections.
Overall, in our code, we aimed to follow the best practices of modern C++ (we used the C++17 standard, since that is the latest one allowed at our campus). We never performed any manual memory allocation using new/delete, but instead used smart pointers (std::unique_ptr). Since lower-level file operations were inevitable (modern C++ does not provide an alternative to C networking APIs yet), we had to use manual open() and close() for file descriptors, but we made sure to use RAII principles (the object destructor is responsible for closing file descriptors). Other modern features include the use of the Filesystem library (std::filesystem) for performing file system operations such as path joining, checking the existence of a file or a directory, creating a directory, changing working directory, etc.
Config file
Our program accepts a simplified version of the Nginx config file.
Various directives are allowed in the configuration file. Directives are divided into simple directives and block directives. A simple directive consists of the name and parameters separated by spaces and ends with a semicolon (;). A block directive has the same structure as a simple directive, but instead of a semicolon, it ends with a set of additional instructions surrounded by braces ({ and }). If a block directive can have other directives inside braces, it is called a context (examples: server and location contexts).
Directives placed in the configuration file outside of any contexts are considered to be in the “global” context. Unlike Nginx, there is no http context for our program. server directives must be in the global context. Comments are allowed: the rest of a line after the # sign is considered a comment.
Here is a more detailed description of the directives allowed in each of the three allowed contexts:
1. “Global” context:
At least one server block is mandatory in the global context.
Allowed directives inside global context:
| Directive | Multiple allowed | Duplicates allowed | Is optional | Default value | Number of arguments |
|---|---|---|---|---|---|
server | yes | yes (ignore) | no | - | n/a (block) |
root | no | no | yes | inherited or “html” | 1 |
index | yes | yes | yes | index.html | no limit |
error_page | yes | yes | yes | inherited or none | no limit (at least 2, last is URI) |
autoindex | no | no | yes | inherited or off | 1 (on/off) |
client_max_body_size | no | no | yes | inherited or 1m | 1 |
2. server context:
The first server block defined for a given IP:port combination becomes the default server for that IP:port. If multiple servers have the same server_name, it is allowed, but a warning will be issued that they will be considered one server (i.e., all the subsequent duplicate servers will be ignored).
Allowed directives inside server context:
| Directive | Multiple allowed | Duplicates allowed | Is optional | Default value | Number of arguments |
|---|---|---|---|---|---|
listen | yes | no | yes | INADDR_ANY:http | 1 |
server_name | yes | no | yes | "" | no limit |
root | no | no | yes | inherited or “html” | 1 |
index | yes | yes | yes | index.html | no limit |
error_page | yes | yes | yes | inherited or none | no limit (at least 2, last is URI) |
location | yes | no | yes | / | block (see below) |
autoindex | no | no | yes | inherited or off | 1 (on/off) |
client_max_body_size | no | no | yes | inherited or 1m | 1 |
cgi_handler | yes | no | yes | - | 2 (ext and interpreter) |
3. location context:
Allowed directives inside location context:
| Directive | Multiple allowed | Duplicates allowed | Is optional | Default value | Number of arguments |
|---|---|---|---|---|---|
root | no | no | yes | inherited or “html” | 1 |
autoindex | no | no | yes | inherited or off | 1 (on/off) |
client_max_body_size | no | no | yes | inherited or 1m | 1 |
index | yes | yes | yes | inherited or index.html | no limit |
error_page | yes | yes | yes | inherited or none | no limit (at least 2, last is URI) |
cgi_handler | yes | no | yes | inherited or none | 2 (ext and interpreter) |
limit_except | no | no | yes | GET POST | no limit |
upload_store | no | no | yes | - | 1 |
return | no | no | yes | - | 1 or 2 (code URL) |
In terms of C++, each of the above 3 contexts is its own class: GlobalConfig, ServerConfig, and LocationConfig. There is only one GlobalConfig object since only one config file is allowed. Each GlobalConfig object can have multiple ServerConfig objects, and each ServerConfig object can have multiple LocationConfig objects.
Socket programming
Even in modern C++, network programming requires dealing with low-level C libraries and APIs that were designed at the dawn of the Internet 3 There are third-party C++ libraries that abstract away much of this, but the standard library lacks high-level networking. . This is one of the frequently cited limitations of C++. Various proposals to modernize this aspect of the language have been raised and are currently under consideration by the C++ standards committee.
So, in order to write a web server in C++, if we don’t want to use third-party libraries, we must get ready to do some good old C programming! One of the main concepts to grasp is that of a socket.
In UNIX-like systems, a socket is a software abstraction that serves as an endpoint for sending and receiving data. The Berkeley Sockets API, which standardized this concept, was designed to be protocol-agnostic from its inception, supporting different communication domains.
Two common domains are:
- Internet Sockets (AF_INET/AF_INET6): Used for communication over a network. These sockets are identified by an IP address and a port number. They do not have a visible representation in the file system.
- Unix Domain Sockets (AF_UNIX): Used for inter-process communication on the same host. These are more efficient than network sockets for local communication and are represented by a special file in the filesystem.
Regardless of the type, when a socket is created, the kernel returns a file descriptor — a small integer — that the process uses to read from, write to, and manage the socket. This exemplifies the “everything is a file” philosophy in UNIX-like systems.
There are plenty of tutorials available out there that guide you through the basics of socket programming, so I won’t rehash them here. For example, see this article.
Here are the key C library functions that we will need, categorized by the header in which they are defined:
#include <netdb.h>getaddrinfo()for converting the human-readable IP:host combinations (provided in config file) to C-ready data structuresstruct addrinfo, to be used in the next functions
#include <sys/socket.h>:#include <fcntl.h>:fcntl()for setting the sockets to non-blocking mode
#include <poll.h>:poll()for asking the OS kernel which fds are “ready” to be processed
The main server loop (poll)
poll() is one of the most important functions for the web server. It is a system call that allows the program to monitor multiple file descriptors to see if they are ready for input/output operations (reading or writing) without blocking.
The heart of the server is an infinite loop (the “event loop”) that calls poll() on every iteration. By passing certain parameters to poll(), we are basically telling the kernel (of the operating system) which file descriptors we are interested in, and for what “events” — we tell poll() whether we are interested in reading from (POLLIN) or writing to (POLLOUT) a file descriptor, or both (e.g., “tell me when file descriptor listen_fd_1 has a new connection,” “tell me when file descriptor connection_fd_1 has data to read,” or “tell me when file descriptor connection_fd_2 is ready to accept more data to write”).
When poll() is called, our server program sleeps (does not consume CPU) until one or more of the registered events occur, or a specified timeout expires.
When poll() returns, it tells us which file descriptors (sockets) are “ready” and for which events. “Ready” means that you can now safely read from or write to that file descriptor without worrying that that read or write might “block”, i.e., freeze the program (e.g., while waiting for user input on stdin). We then iterate through these ready file descriptors and perform the non-blocking input/output operations (like accept() to accept new connections, read()/recv() to read incoming messages, and write()/send() to send back HTTP responses).
This is what allows the server to constantly be “listening” without consuming excess resources. poll() lets us pass responsibility from our program to the OS kernel. The kernel knows how to do this job better than most any code that we can write. Kernels have had this kind of capability — checking the status of files to see which ones are “ready” — since before the invention of the web.
This event loop continues indefinitely until a UNIX signal (SIGINT) is received. A signal handler ensures that the server shuts down gracefully after performing any necessary cleanup of resources (closing file descriptors, freeing memory, etc.).
HTTP messages
Parsing of incoming request messages:
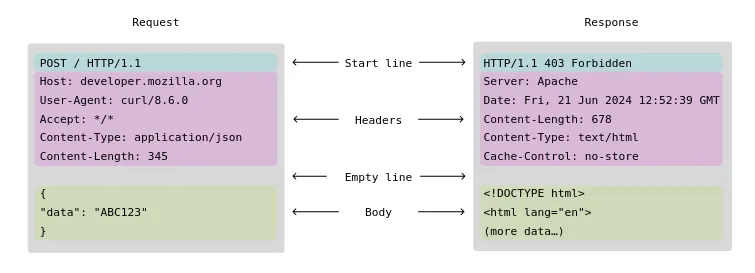
When a request arrives on our server, the first thing the server must do is to parse it and make sure that it is a valid HTTP request (follows the rules of the HTTP protocol, only version HTTP/1.1 in our case). Again, I won’t go through the details here myself since there are already great guides out there. MDN in particular is a fantastic resource with very readable details on the HTTP protocol (and much more regarding the web). We must keep in mind things like case (in)sensitivity (e.g., header name is case-insensitive), that line separator is CRLF (\r\n, not \n), and that the headers are separated from the body by a blank line (\r\n\r\n). Here is an image from MDN that I find very helpful:
Our web server supports three HTTP methods: GET, POST, and DELETE. HTTP methods indicate the purpose of the request and what is expected if the request is successful:
GET: Tells the server to retrieve a resource at a specified location.POST: Submits some data to the specified resource, often causing a change in state on the server.DELETE: Deletes the specified resource.
If the requested method (always in the first line of an HTTP request) is none of these three, the request is considered invalid by our server, and an error response is sent back, e.g.:
HTTP/1.1 501 Not Implemented
Content-Type: text/html
Content-Length: 158
Server: Webserv
Date: Sun, 17 Aug 2025 21:31:41 GMT
<html>
<head>
<title>501 Not Implemented</title>
</head>
<body>
<h1>501 Not Implemented</h1>
<p>The server does not support the facility required.</p>
</body>
</html>The server also checks whether the value of the Content-Length header matches the actual size of the content received. The incoming request may also be “chunked” — chunked encoding is a mechanism in HTTP/1.1 that allows the sender to transfer a request or response body as a series of “chunks” without knowing the total size in advance. So the server must “unchunk” it. Instead of Content-Length, the sender includes the header Transfer-Encoding: chunked, which acts as a signal to the receiver (our server) that the body will not be a single block of data of a known size, but will instead follow a special format.
Generating response messages:
After successfully parsing and validating a request, the server starts working on generating an appropriate response. In our C++ code, this is done by separate classes for GET, POST, and DELETE (in addition to a class for handling unknown/bad requests), which all inherit from a HTTPRequest abstract base class with the main pure virtual function being generateResponse().
The server must never do a read or a write operation without going through poll() (to be sure that the operation will be non-blocking). So generateResponse() acts like a state machine. Each time generateResponse() needs to read from or write to a file, it does some work, saves its current working state at the point where it needs to read or write, registers the read or write file descriptor with poll, and returns. When poll() says the file descriptor is ready for reading/writing, the generateResponse() function will be called again, recognize (based on the previously saved state) that this is not the first time it is being called, and continue where it left off last time. Every time it returns, the main server loop checks if the response is ready, so that it can be sent to the client.
The requested resource path is always built by adding the URI to the root. E.g., if the first line of the request is GET /some_file_or_dir HTTP/1.1 and the root (set in the configuration file) is /var/www/my_website/, the resource path is root + URI = /var/www/my_website/some_file_or_dir. And if the first line of the request is GET / HTTP/1.1, the resource path is root + URI = /var/www/my_website/ (same as root).
For GET responses, the generateResponse() function checks whether the requested path (root + URI) exists or not; otherwise, it is an error (404). If the requested path is a file (except for CGI files), the server reads the file and sends its contents as the body of the response. If the requested resource is a directory, the server checks if an index file has been set in the server configuration file. If such a file is found in the directory, then this file is chosen for the response; otherwise, an error 404 is returned.
For POST, the URI, instead of being a file or directory, represents an endpoint that will process the data the client is sending. POST /submit-form HTTP/1.1 doesn’t mean there’s a file or directory named submit-form. It means there is a piece of logic on the server, associated with the /submit-form path, that knows what to do with the incoming form data. For form data, POST usually hands over the task to a CGI program. If there is no CGI program set up at the requested URI, it is considered to be a request to upload data to a file on the server. In our particular case, uploads are only allowed if a location block is provided in the configuration file with an upload_store directive. This will allow uploads for that particular location (URI/endpoint) only. For example,
location /upload {
upload_store /path/to/upload/directory;
} This will allow uploads only for requests such as POST /upload HTTP/1.1, but other requests like POST /some-uri HTTP/1.1 will get an error. The request body for POST requests is usually not plain text that can be written to a file; the body is usually encoded. Once a valid upload request is received, the POST version of generateResponse() must parse the encoded request body. Uploads via POST requests almost always use the multipart/form-data encoding, identified by the Content-Type header (see RFC for more details on the syntax). For simple form data, application/x-www-form-urlencoded encoding may be used. Less commonly, for file uploads, application/octet-stream might be used to send raw binary data. It is also possible to see a non-encoded media type, such as Content-Type: text/plain, Content-Type: text/html, or Content-Type: application/json, etc., in which case the body’s raw data is saved in a file with an appropriate extension. If a file upload is successful, a 201 Created response is sent; otherwise, an appropriate response, such as 415 Unsupported Media Type is sent.
For DELETE, the URI refers to the file or directory that should be deleted. In our server, DELETE is disallowed by default in all locations, and must be enabled manually for individual locations. For example, if DELETE is enabled in the /uploads location, for a request DELETE /uploads/photo123.jpg HTTP/1.1, if the file exists, the server will delete the file and send a 200 success response (202 or 204 can also be sent). If the file does not exist, it will be a 404 Not Found response. If the resource is not inside the upload_store directory (e.g., DELETE /index.html HTTP/1.1), it will be a 403 Forbidden response.
Regardless of the method requested, redirections in our server are configured using a return directive in the config file. For example, the config file might contain:
location /redirect-demo {
return 301 "https://www.youtube.com/watch?v=dQw4w9WgXcQ";
}Then any request to the URI /redirect-demo will be redirected to the URL https://www.youtube.com/watch?v=dQw4w9WgXcQ. A redirect response might be:
HTTP/1.1 301 Moved Permanently
Content-Type: text/html
Location: https://www.youtube.com/watch?v=dQw4w9WgXcQ
Content-Length: 105
Server: Webserv
Date: Mon, 18 Aug 2025 14:15:11 GMT
<html>
<head>
<title>301 Moved Permanently</title>
</head>
<body>
<h1>301 Moved Permanently</h1>
</body>
</html>CGI
The Common Gateway Interface (CGI) is a standard protocol that allows a web server to execute external programs (CGI scripts) to process and generate content for web requests. Just like HTTP/1.1, the CGI/1.1 specification is described in an RFC. Legacy CGI is not very commonly used nowadays, as much more performant and feature-rich alternatives now exist, such as FastCGI, servlets, and web frameworks. Our server uses CGI/1.1 for educational purposes.
Our config file allows a cgi_handler directive, which takes two arguments: an extension and the path to a handler for that extension. The interpreter can be for any language, e.g. Perl, PHP, or Python. For example, the following can be specified in the config file:
server {
listen localhost:9743;
server_name localhost;
root ./assets/default_website;
cgi_handler .py /usr/bin/python3;
location /cgi-demo {
index hello.py;
}
}Here, the cgi_handler is provided in the server context and will be inherited by any location blocks within that server block. What this means is that any request for a resource name ending with .py will be considered a CGI request within this server block. In addition, requests to the /cgi-demo location will also be considered CGI requests since its index file ends with .py.
The general idea is that the server:
- Identifies a requested resource as a CGI script (e.g.,
/cgi-demo/hello.py). - Prepares an environment for the script, packing all the request details (method, headers, query string, etc.) into environment variables.
- Executes the script using the configured interpreter (e.g.,
/usr/bin/python3). - Pipes the request body (if any, like from a POST) to the script’s standard input (
stdin). - Reads the script’s standard output (
stdout). This output contains the response headers and body that the server should send back to the client. - Waits for the script to terminate and cleans up.
Just like network programming, modern C++ is annoyingly lacking in features to create, manage, and communicate with sub-processes (child processes). So we must again go back to C APIs. We will use fork() to create a child process, execve() to execute the CGI program, pipe() (with the help of dup2()) to communicate with the child process. waitpid() is used to check the status of the child process, and kill() can be used to terminate the process if needed.
The CGI protocol has very specific rules (just like the HTTP protocol) about how a request is passed to the CGI process. The most critical part is the preparation of environment variables that must be passed to the CGI program (via the execve system call). Here are the essential ones based on the CGI/1.1 specification:
| Variable | Description | Example Value |
|---|---|---|
GATEWAY_INTERFACE | The CGI version. | CGI/1.1 |
SERVER_PROTOCOL | The protocol of the request. | HTTP/1.1 |
REQUEST_METHOD | The HTTP method. | GET, POST, etc. |
REQUEST_URI | The full, original request URI. | /path/to/script.py?user=test |
SCRIPT_FILENAME | The absolute filesystem path to the script. | /var/www/html/path/to/script.py |
SCRIPT_NAME | The virtual path to the script. | /path/to/script.py |
QUERY_STRING | The part of the URI after the ?. | user=test |
CONTENT_TYPE | The Content-Type header from the client request. | application/x-www-form-urlencoded |
CONTENT_LENGTH | The length of the request body. If the request was chunked, this should be the total size of the unchunked body. | 15 |
SERVER_NAME | The server’s hostname or IP. | example.com |
SERVER_PORT | The port the server received the request on. | 80 |
REMOTE_ADDR | The IP address of the client. | 192.168.1.10 |
All other headers from the request must also be passed as environment variables. The convention is to prefix them with HTTP_, convert the header name to uppercase, and replace hyphens (-) with underscores (_). For example, User-Agent becomes HTTP_USER_AGENT and Accept-Language becomes HTTP_ACCEPT_LANGUAGE.
We then use the standard UNIX way to create the child process. Two pipes are needed to communicate with it: one for our server to write the request body to the CGI’s stdin, and the other for our server to read the response from the CGI’s stdout. We use a CGISubprocess class for this:
CGISubprocess::CGISubprocess()
{
if (pipe(_pipe_to_cgi) != 0)
throw std::runtime_error("Failed to create pipe to CGI: " + std::string{strerror(errno)});
setNonBlocking(_pipe_to_cgi[0]);
setNonBlocking(_pipe_to_cgi[1]);
if (pipe(_pipe_from_cgi) != 0)
{
close(_pipe_to_cgi[0]);
close(_pipe_to_cgi[1]);
throw std::runtime_error("Failed to create pipe from CGI: " + std::string{strerror(errno)});
}
setNonBlocking(_pipe_from_cgi[0]);
setNonBlocking(_pipe_from_cgi[1]);
}
void CGISubprocess::createSubprocess(const std::filesystem::path &filePathAbs, const std::string &interpreter)
{
// fork (create a duplicate of the current process)
_pid = fork();
if (_pid == -1)
throw std::runtime_error("Failed to create fork for CGI: " + std::string{strerror(errno)});
// in child
else if (_pid == 0)
{
// change current working directory to script directory
std::filesystem::current_path(filePathAbs.parent_path());
close(_pipe_to_cgi[1]); // Close write end of the pipe (parent will write to it)
dup2(_pipe_to_cgi[0], STDIN_FILENO); // redirect stdin to read end of pipe_to_cgi
close(_pipe_to_cgi[0]); // close redirected fd
close(_pipe_from_cgi[0]); // close read end of the pipe (parent will read from it)
dup2(_pipe_from_cgi[1], STDOUT_FILENO); // redirect stdout to write end of pipe_from_cgi
close(_pipe_from_cgi[1]); // close redirected fd
// prepare args for execve (interpreter is the program name and script file is the argument, like running `python3 hello.py`)
char *args[] = {const_cast<char *>(interpreter.c_str()), const_cast<char *>(filePathAbs.c_str()), NULL};
// execve
if (execve(args[0], args, _envp.data()) == -1)
{
// can also simply use std::exit but it won't clean up the local objects (destructor will not be called)
throw std::runtime_error("execve failed: " + std::string{strerror(errno)});
}
}
// in parent
else if (_pid > 0)
{
_subprocessStarted = true;
// close unneeded pipes
close(_pipe_to_cgi[0]);
close(_pipe_from_cgi[1]);
}
}We then register the two remaining open file descriptors in the parent process with poll() (one to write to the CGI and one to read from it), which will tell us whether the file descriptors are ready for reading/writing or not. After writing to the child and reading back from it successfully, all that remains to be done is to send a response to the client. The response we read from the CGI is almost a full response, but not quite. It can e.g., contain the Status: 200 OK header, which we should convert to a proper start line HTTP/1.1 200 OK. This is now the full response and can finally be sent to the client.
Closing remarks
So hopefully, this provides some insight into the inner workings of a web server, a technology that lies at the heart of the web that we all interact with every day. Admittedly, it can be frustrating to go back to understand old-school technologies and use verbose C/C++ code to implement what modern languages and frameworks can achieve in a snap of a finger. But modern frameworks can only do that because somebody else has already done the difficult work, notwithstanding the fact that a surprisingly large amount of infrastructure in the present day still runs on decades-old technologies. I, for one, learned a great deal by working on this project and expect these lessons to be useful in a wide range of development tasks.